MLOps for online machine learning
Why do we need online MLOps?
The term “MLOps” is short for Machine Learning Operations. This topic brings together the practices of Machine Learning and Operations (as the name might suggest 😋). Some people like to think of it as the ML equivalent of “DevOps”. MLOps focuses on optimizing the development and operational lifecycle of ML systems, as illustrated in the following sketch.
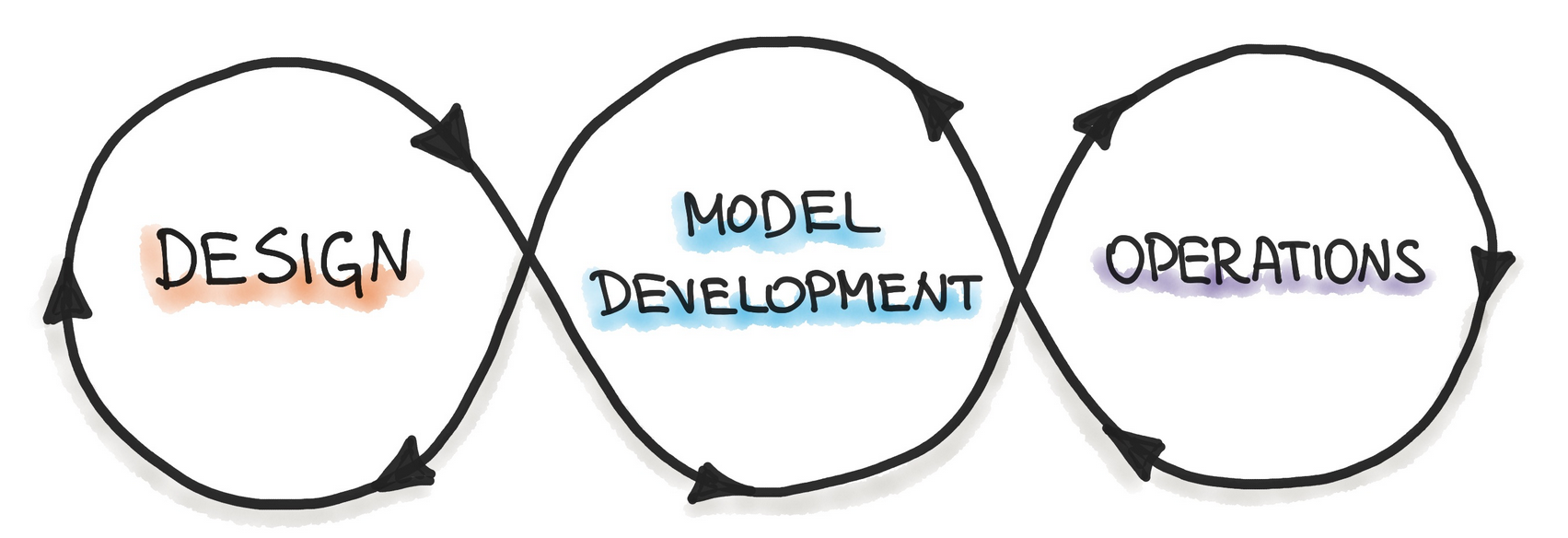
ML Systems do not only consist of the ML Code (the model, training, etc.) but are so much more. Even though it’s very nice to finally train a model that generates good results inside of a local jupyter-notebook, that’s only a fraction of the work that needs to be done to actually ship a model to production and serve it to customers, have it monitored, and so on…
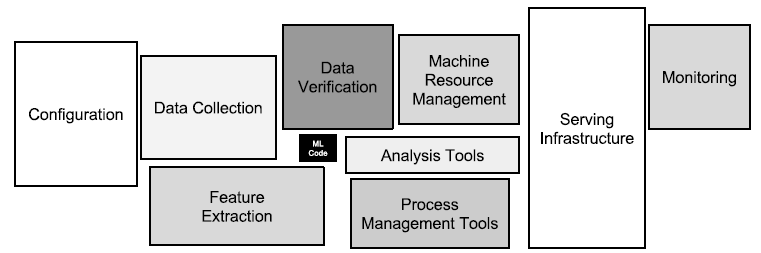
This graphic (from a paper written by D. Sculley et al.) depicts what a typical ML System may consist of. It is clear to see that the ML Code is only a small part of the big picture. The lifecycle of such a complex system needs to be managed for it to run smoothly. This is where MLOps comes into play.
It focuses on streamlining and automating the lifecycle of machine learning models, from development to deployment and maintenance. MLOps aims to create a collaborative and efficient (partly or fully automated) workflow to enable faster, reproducible, and more effective deployment of AI models into production while also reducing manual efforts and the possibility of human error. Furthermore, MLOps can also handle the infrastructure and processes needed to scale ML applications efficiently. Among others, it involves practices like:
- CI/CD Automation
- Workflow Orchestration
- Versioning
- Continuous ML Training & Evaluation
- ML Metadata Tracking / Logging
- Continuous Monitoring
- Hyperparameter Tuning
- …
The emphasis here lies on reliability, scalability, and governance of machine learning systems. These approaches ensure that AI models remain accurate, efficient, and relevant over time. Tools in this field often provide capabilities for continuous monitoring and management of machine learning models, ensuring they perform as expected and allowing for quick adjustments in response to performance degradation or changing data patterns (also known as Concept Drift, a common problem encountered when transitioning from development to production).
While there are already numerous tools and frameworks available for MLOps, there is still a demand for reliable toolchains that support MLOps end-to-end, especially in “online learning” scenarios.
Online Machine Learning
Online learning describes a special subfield of Machine Learning, in which an online ML algorithm is able to continuously learn and adapt from a stream of incoming data. With this approach, models are updated in real-time as new data arrives, allowing them to respond quickly to changes and new patterns (e.g., Concept Drift). This contrasts with traditional “batch learning,” where a model is trained on a fixed batch of data and doesn’t update until it’s retrained with a new dataset. A popular Python library for online ML (somewhat in the fashion of scikit-learn) is River.
While online models are capable of coping with Concept Drift, they present unique challenges in terms of deployment and operation in production environments. Therefore, there are already efforts to build MLOps tools specialized in online ML. One such tool being developed by some of the developers behind River is Beaver, for example.
Delta
Since I have some experience with online ML (having worked on it privately and for my bachelor’s thesis), I find MLOps very interesting. This led me to consider working on such tooling myself. Additionally, I have a background in automation projects and DevOps, having worked in a network automation team at Deutsche Telekom Technik during my bachelor studies. During this period, I also explored integrating River models with the lightweight web development framework Flask.
So, now that I’ve decided to work on MLOps for online learning, a term I like to call ‘oMLOps,’ one of the first things I needed to figure out was, of course, a name for the project 😉. Since the online ML library is called River, I thought about a place where many rivers cross and interact with each other (or flow in parallel) and came across river deltas, hence the name “Delta”.
Putting jokes aside, the first challenge was to strategize tackling the enormous task of building an MLOps tool and how to realize the different aspects of such a system. My idea is based on the fact that a single instance of an online learner is pretty lightweight. Additionally, River does not work with things like numpy-arrays but with plain Python dictionaries. Since these dictionaries can be easily represented as a JSON payload, integrating River models into a web-service is pretty straightforward…
The core idea
Each ML model is encapsulated within its own microservice or web-service, for example, as its own Docker container or Pod. A single instance of such a container should be as simple as possible as this allows for independent deployment, scaling, and updating. Such a container provides two REST APIs:
-
“Public” API for Training and Inference: This makes the model accessible for real-time predictions and allows for continuous learning by feeding new data via an API call together with a JSON payload.
-
“Management” API: This is crucial for MLOps, enabling monitoring, configuration, and control of the model services. Through this API, developers or other parts of the MLOps system can fetch metrics, update model parameters, and manage the lifecycle of the model.
The more complex part of the MLOps system would be the central “controller software,” which manages all these containers/pods. It facilitates functions such as monitoring, versioning, tuning, among others. This is a more advanced component. It can automatically manage and configure model containers based on various signals like performance metrics, cost, time, etc.
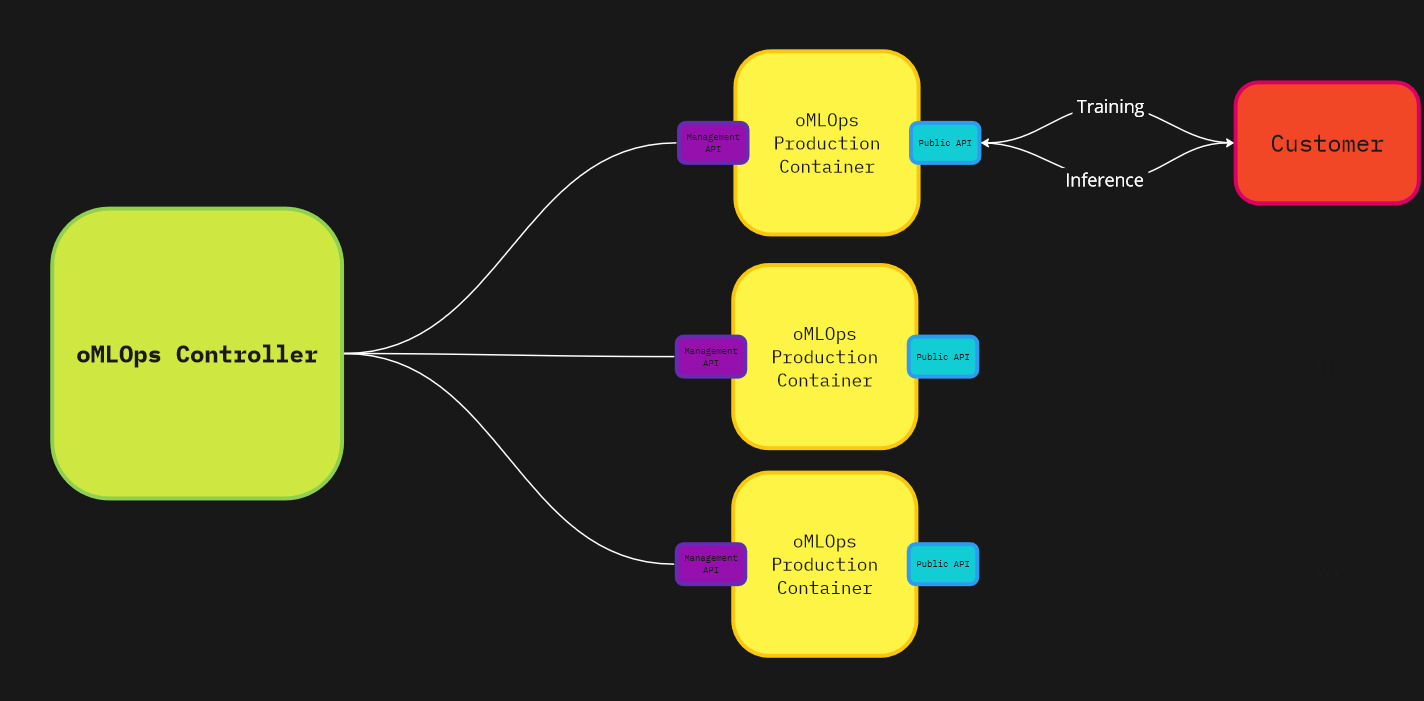
MVP
This vision is indeed ambitious, and the task of building this system should be broken down into smaller, manageable tasks. The first version, the Minimum Viable Product (MVP), focuses on the core functionality of the model microservice. It won’t be a full-fledged version with complete MLOps capabilities, but it will mark the first step of the journey and serve as a foundation for further development.
The result of this first iteration will be a container (or rather, a basic image to build this container) hosting a small Flask web service comprising two different APIs. The service’s core will be a binary classification model from the River library. Initially, this model will be fixed, with plans to make the ‘core-model’ configurable by the user in the future. The “Public” API will expose two endpoints: one for training the model and another for making predictions. The “Management” API will expose a single endpoint for querying metrics, such as the model’s accuracy. A Swagger YAML or JSON file will describe the API. This simple setup will be tested using one of River’s simpler datasets, with tests conducted manually using tools like Postman or Insomnia, or automated.
Implementing automated CI/CD workflows using GitHub Actions to automatically build a container, publish the image, and run automated tests would be beneficial.
The plan for the MVP can be transformed into the following steps:
- Define the ML Model with River.
- Develop the Web Service “Wrapper.”
- Containerize the Web Service.
- Test the Container Locally.
- Automate workflows for building, testing, and publishing (CI/CD Pipeline).
Future course of action
The presented MVP leaves room for a lot of improvements and further features. For instance, the core machine learning model of each container needs to be dynamically defined. This could be achieved by using a configuration file, such as JSON or YAML, which is fed into the container during the build process. Alternatively, users could configure this through a live-service API endpoint. A combination of both methods might be the most effective approach.
Other areas that need to be addressed in future developments (among many more) include:
- Monitoring and logging
- Expanded functionality for the APIs
- Version control
- Scalability
- Hyperparameter tuning
- Validation and error handling
- Security
- Testing
- Documentation and examples
Final words
Thank you very much for reading this far. I intend to use this blog as an informal platform to update on the development process and to help structure my work. If I can also arouse the interest of some readers, that’s a big bonus for me. The code base for the Delta Project can be found in the official repository. Feel free to contact me in any way if you want to chat about the topic (or others) 😁.
Until next time, take care!